 入门教程
入门教程
本教程将通过实际操作向大家介绍如何使用思腾云运行自己的代码,根据本教程中的内容,您将会掌握以下内容:
- 在
思腾云-我的网盘中的数据进行上传与下载(包含文件夹)。 - 在
思腾云-算力市场中租用算力资源,并进行远程连接。 - 在
思腾云-我的任务中任务中安装第三方软件包、以及跑简单的AI代码。
# 用户注册
前往思腾云 (opens new window)官网进行用户注册,立即注册 (opens new window)
注册用户需要输入手机号、密码和验证码,如果是朋友/销售邀请的,可以使用邀请链接进行注册。
# 帐户充值
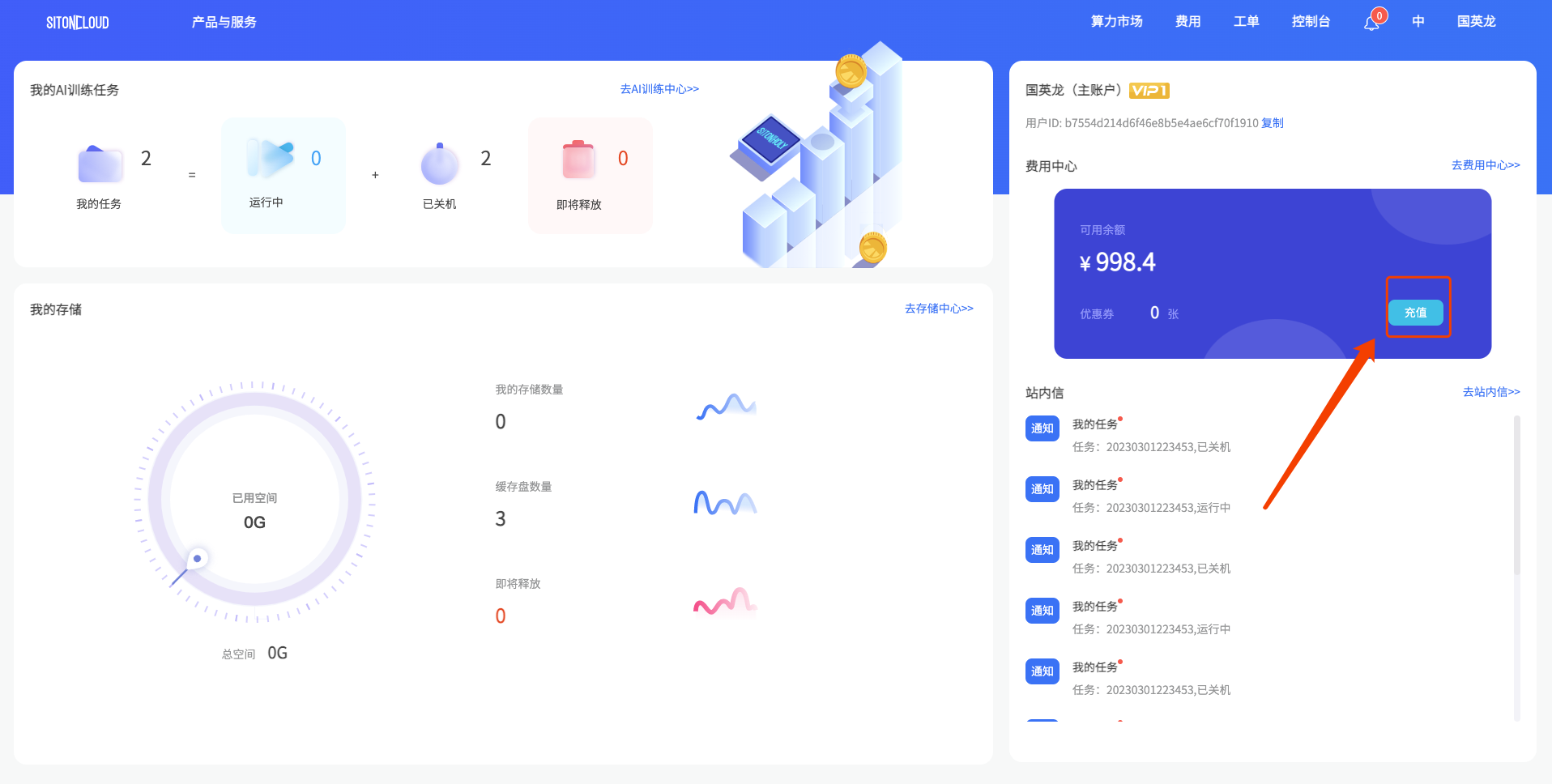
目前思腾云仅支持微信支付,选择对应的金额,点击充值按钮进行充值
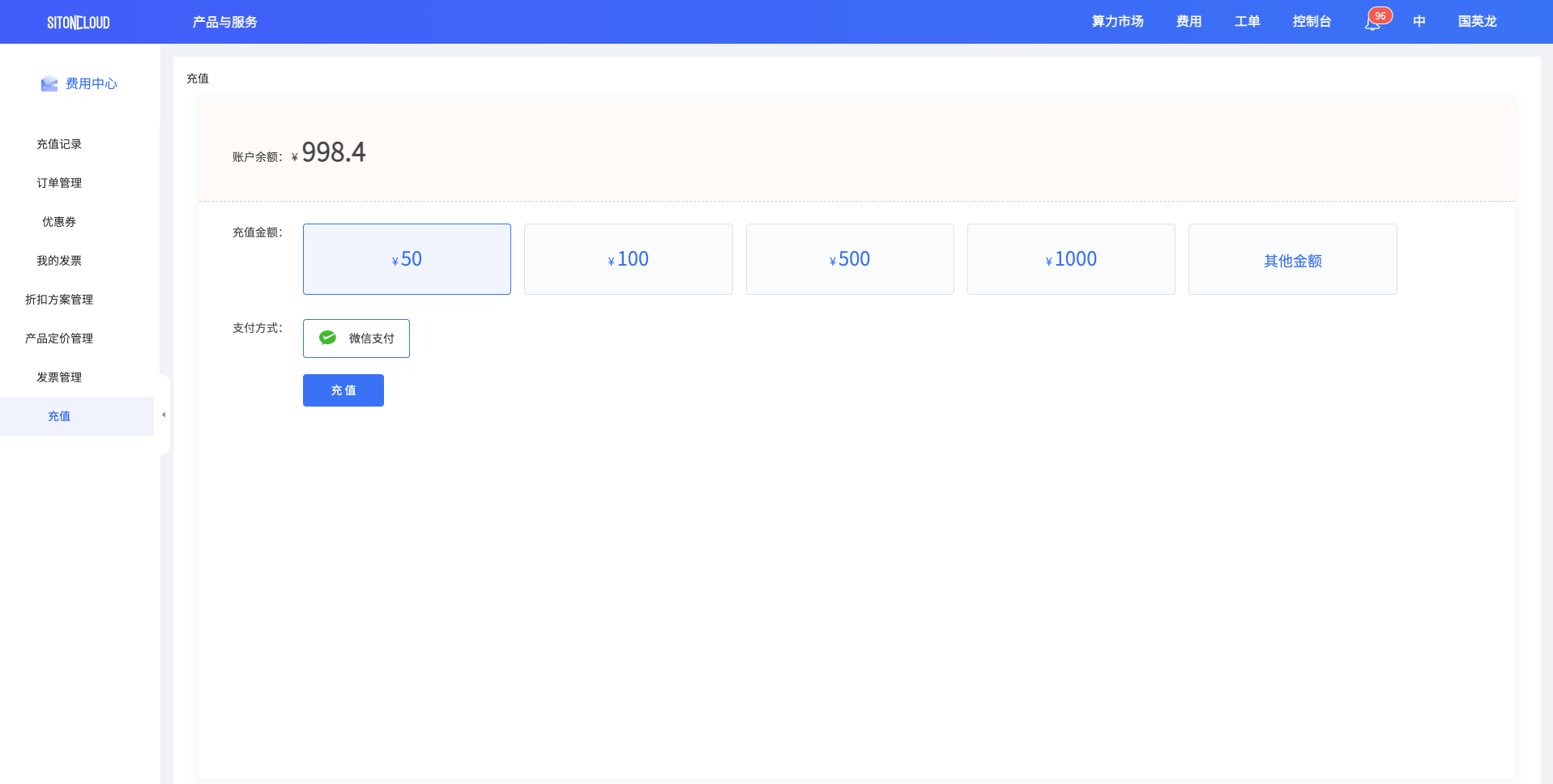
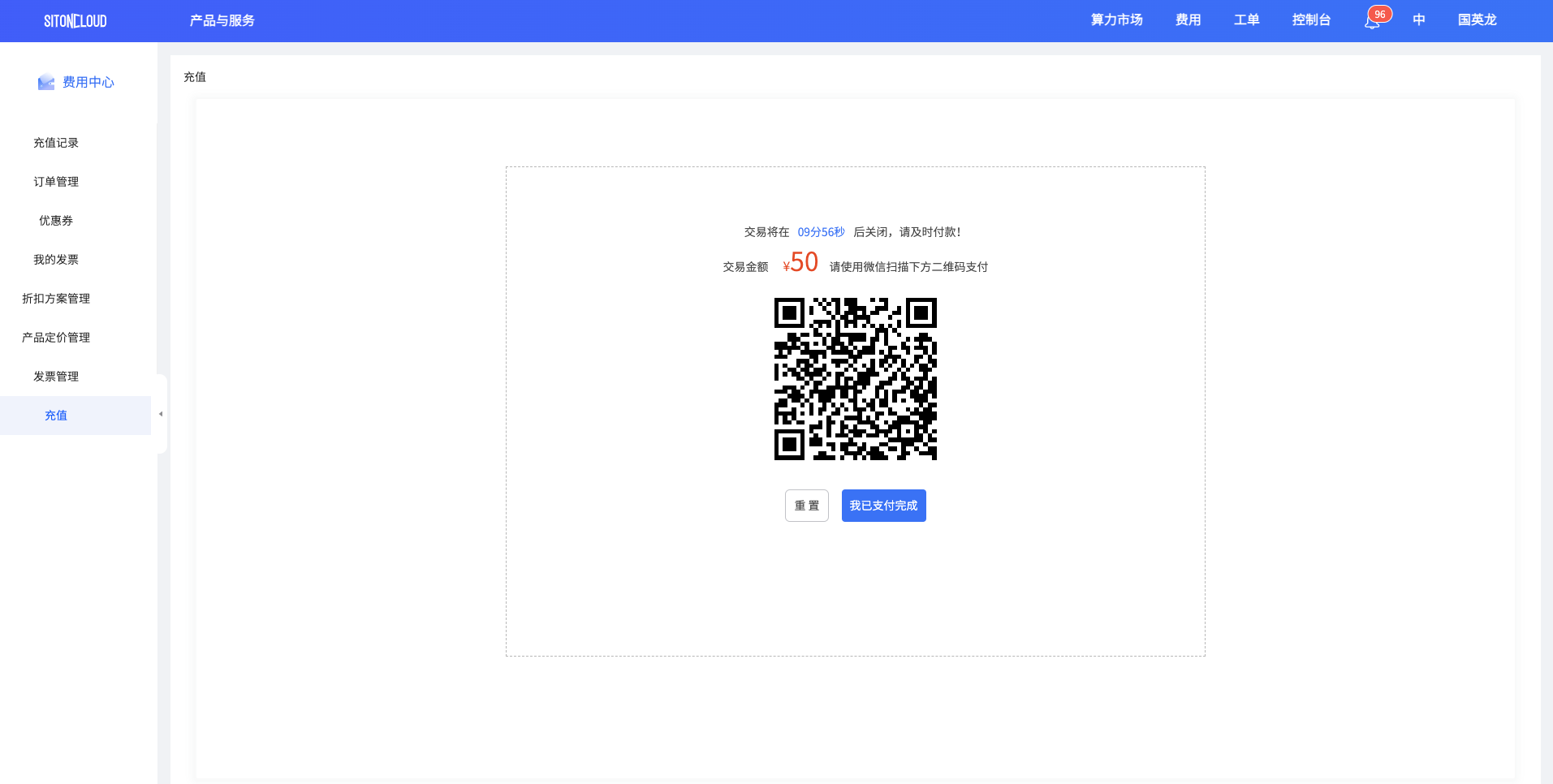
点击充值以后,会跳转到微信支付页面,请使用微信扫码支付。
提示
微信扫码成功以后,大约3-5秒后收到微信服务器返回信息
# 存储配置
提示
思腾云免费为用户提供20GB的数据存储空间
# 初始化网盘
- 点击
控制台首页-去存储中心或者点击左上角产品与服务-我的网盘进行初始化
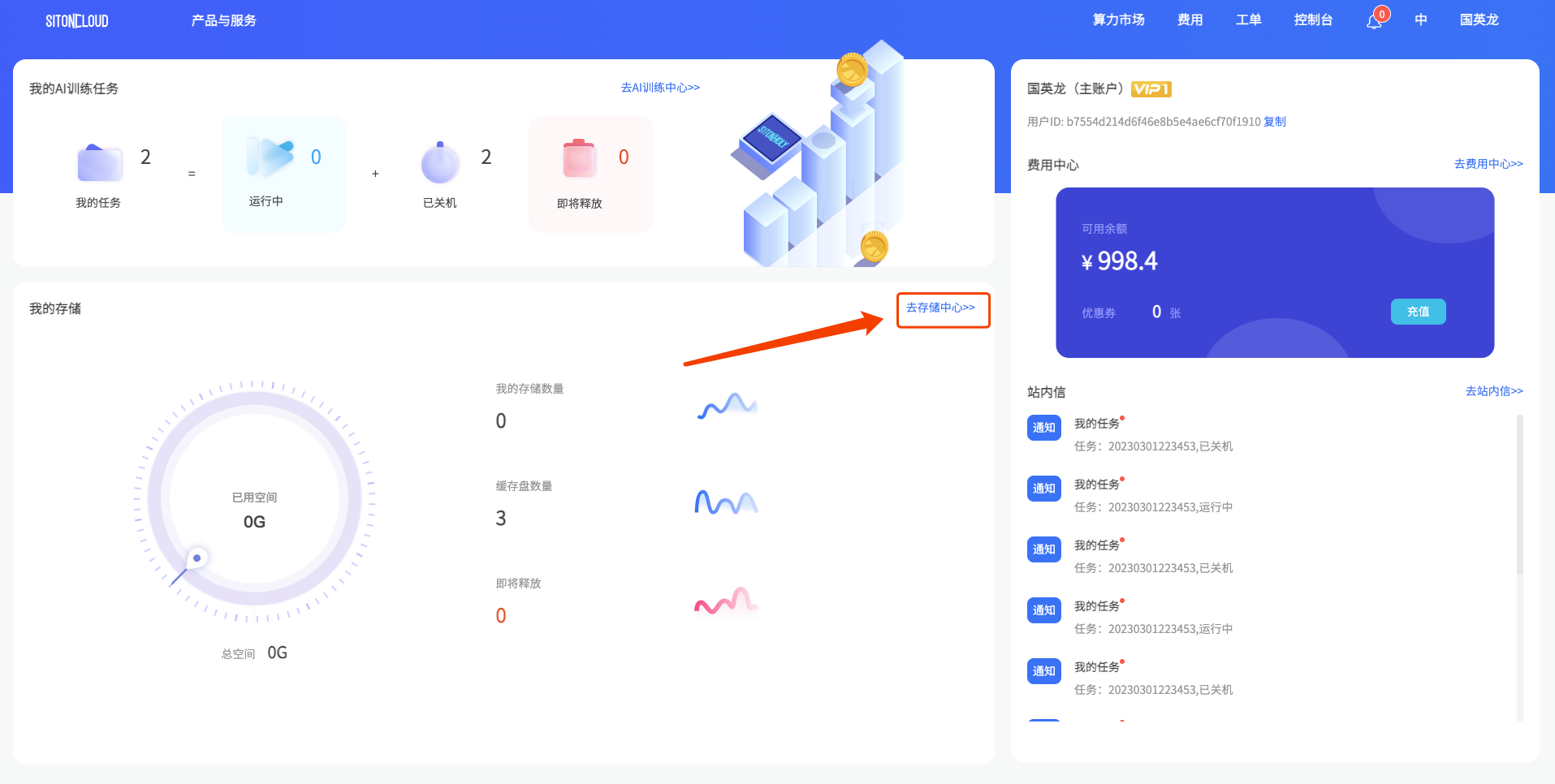
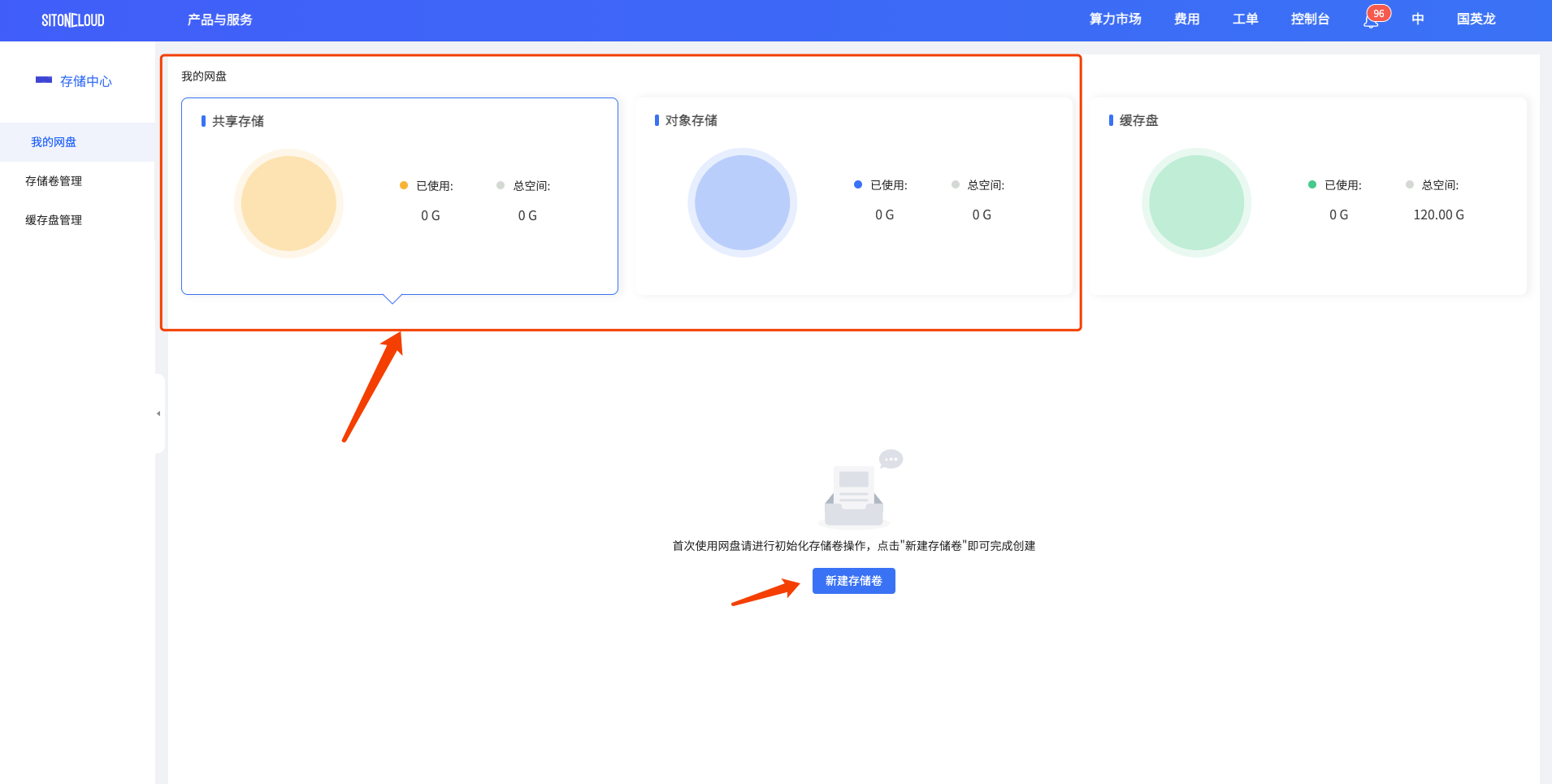
- 选择存储类型点击
新建存储卷即可进行初始化
注意
注意:目前思腾云仅支持对象存储
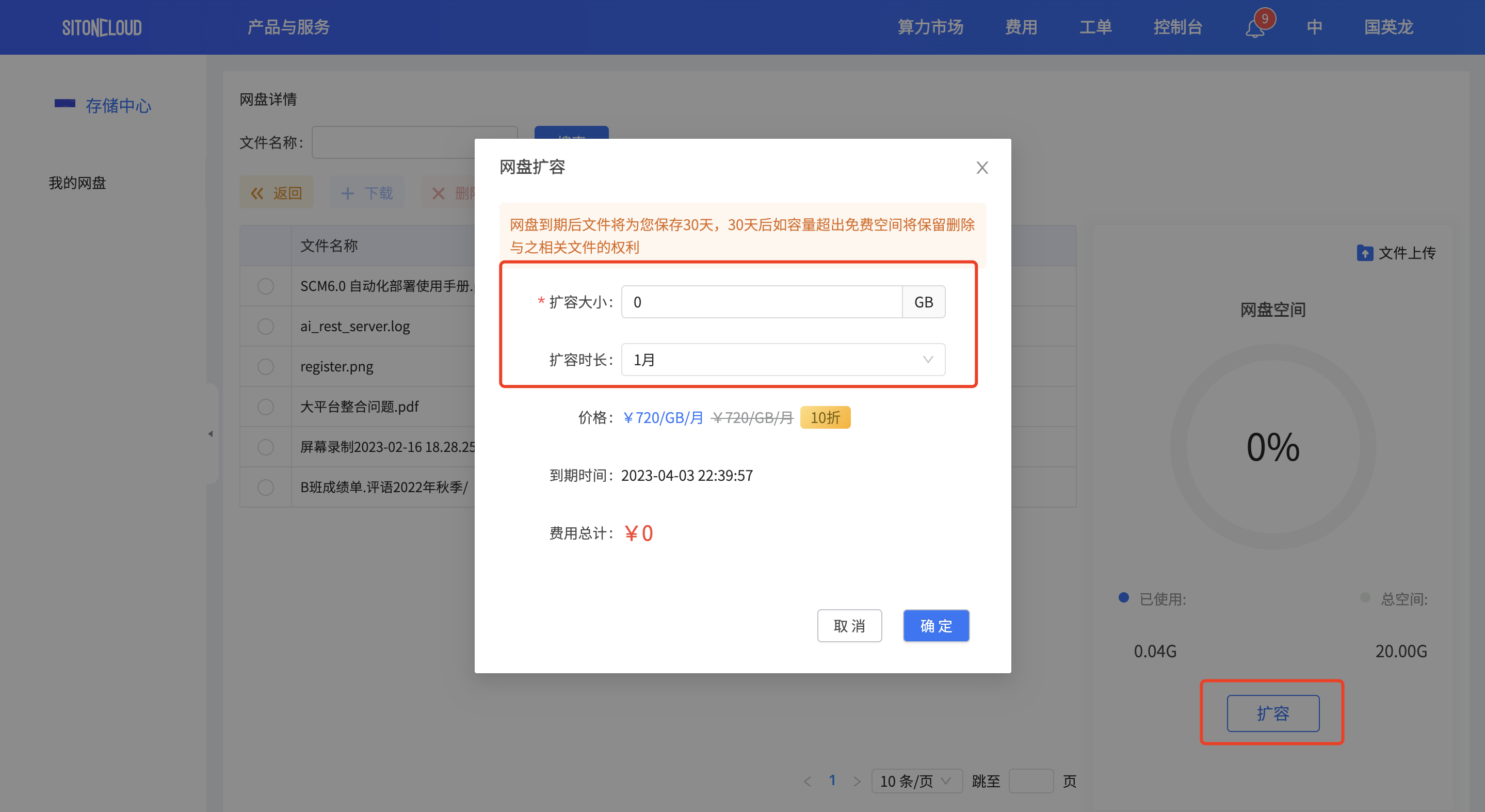
# 网盘扩容
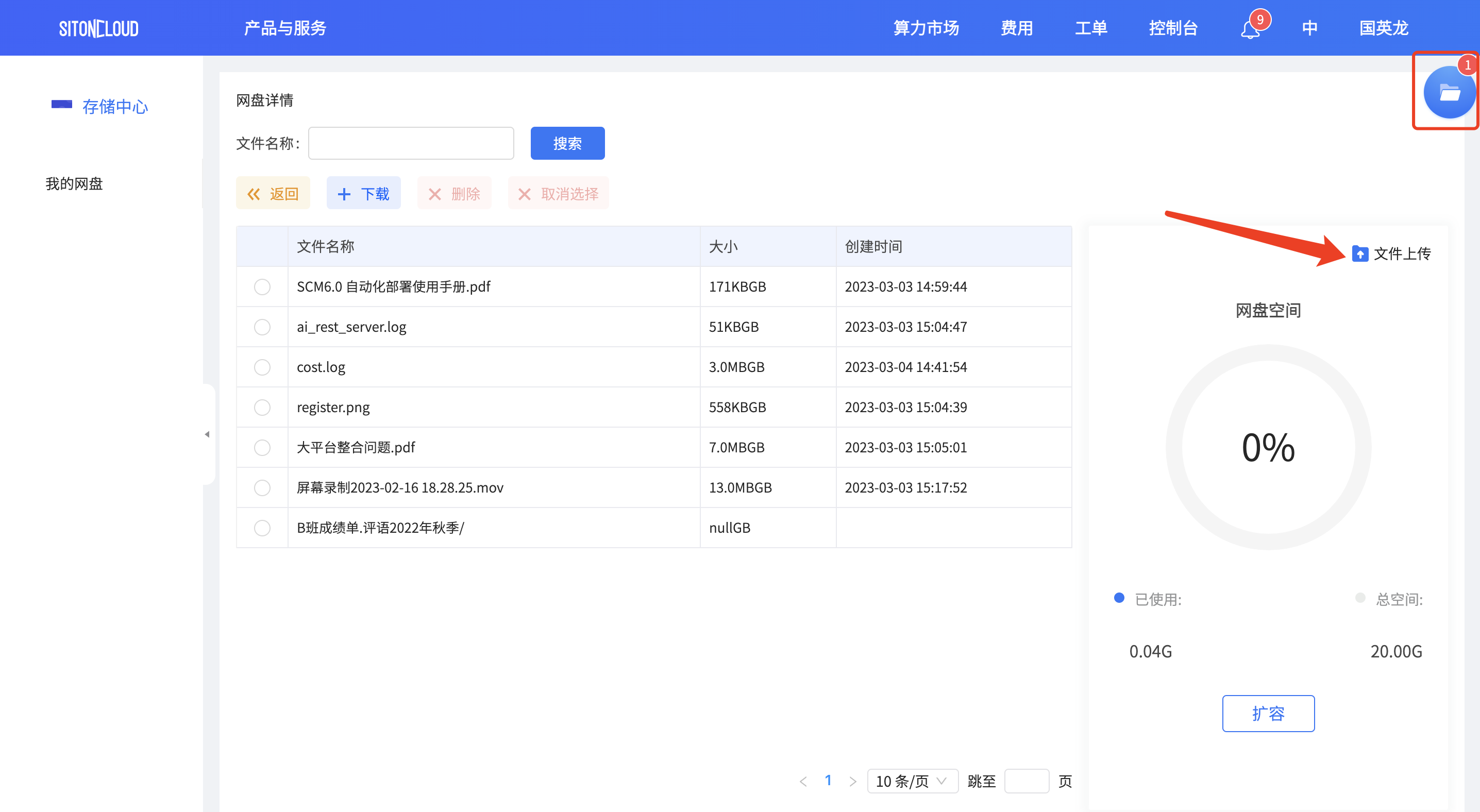
# 上传数据
温馨提示
数据上传过程中,会自动挂后台上传,刷新浏览器会导致上传中断
# 购买算力资源
用户可在算力市场界面进行选购,根据需求进行区域、运算卡数、运算卡显存大小、价格及算力型号的筛选后可查询符合相关条件的算力卡。
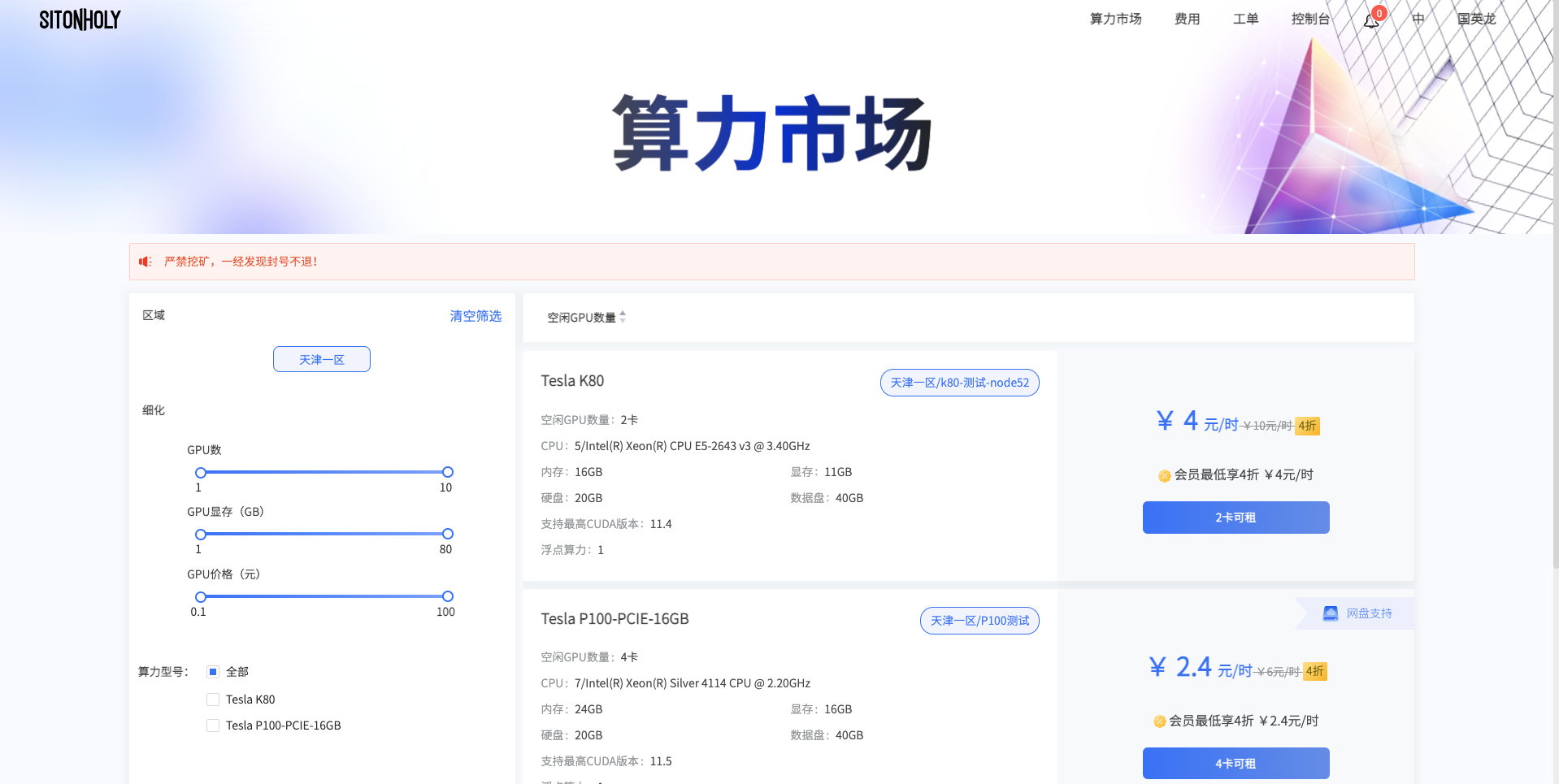
根据上图所示,点击所要选购的算力卡上的8卡可租按钮后,会跳转至算力市场订单详情界面。填写所选运算卡数量、平台镜像信息后界面会自动计算相应价格,便于用户进行核对及查看。若当前用户有优惠券,可选择优惠券后再点击立即创建按钮即可完成创建任务。
目前思腾云支持:按量计费与包天包月两种计费模式
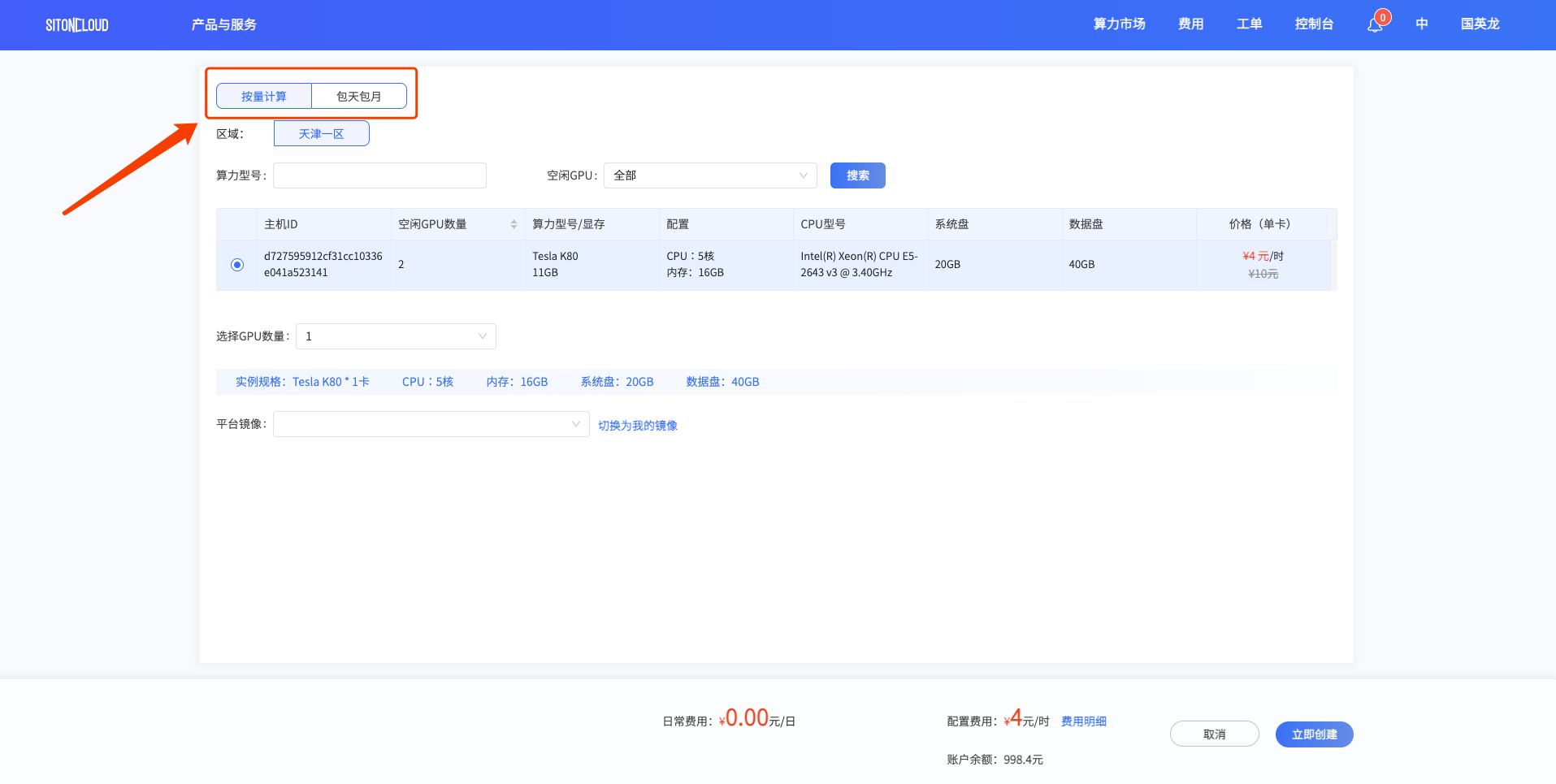
订单创建成功后自动跳转至我的任务。在我的任务模块中,可查看当前任务的详细信息。
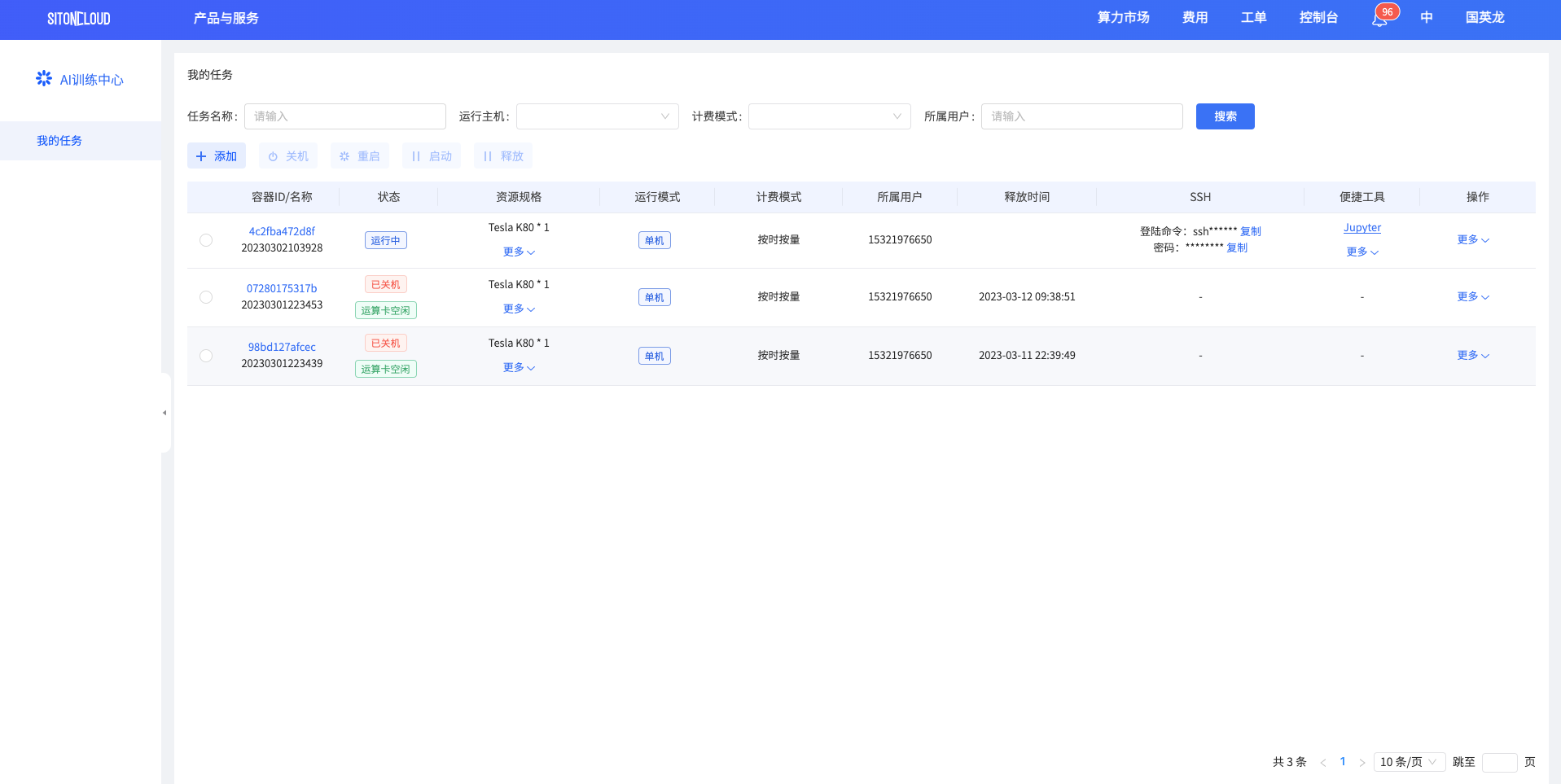
# 远程连接任务
任务状态由创建中变为运行中后,会生成SSH访问地址以及密码,
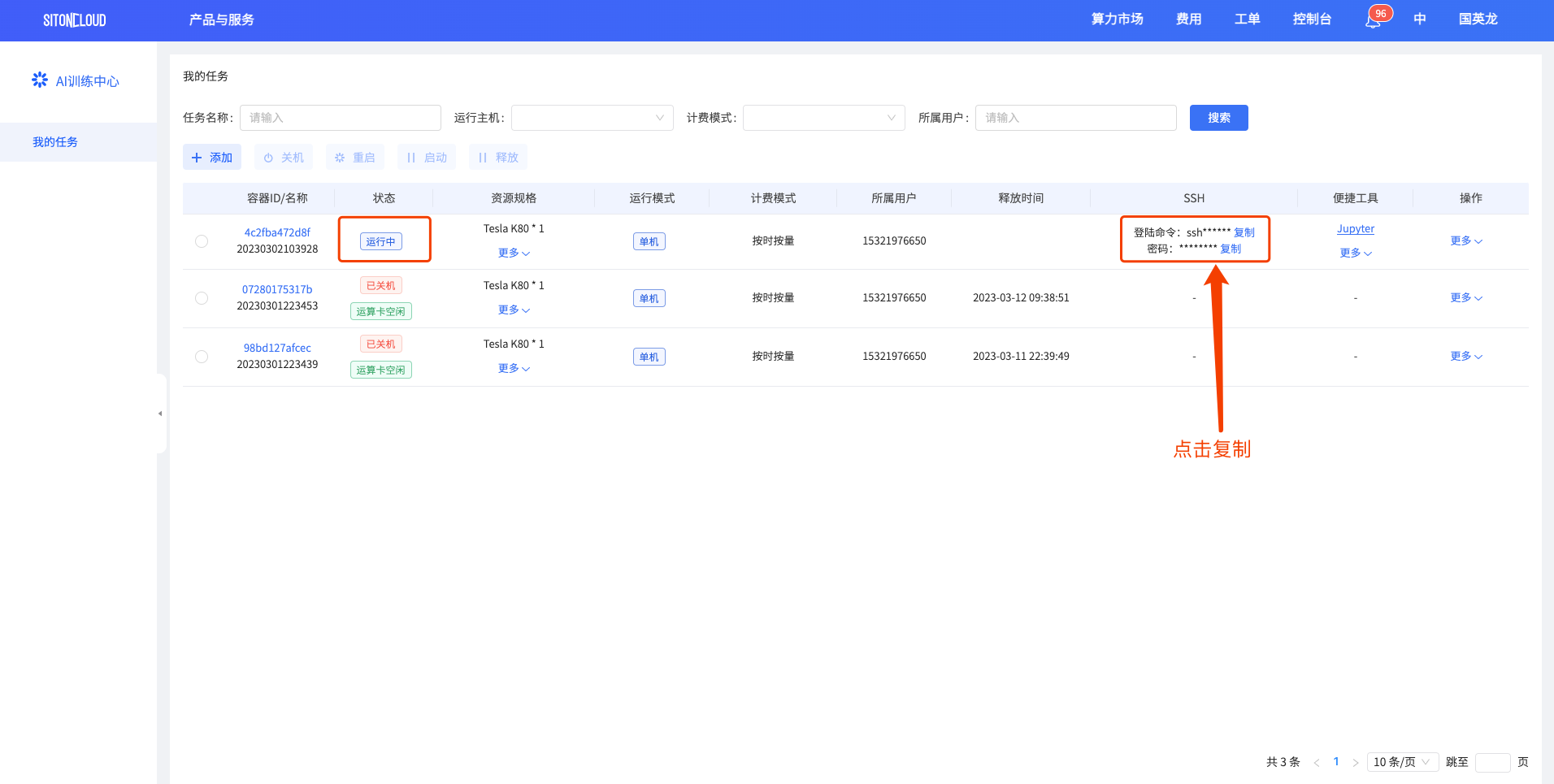
- 复制SSH链接,本地打开终端/CMD/Shell,粘贴SSH链接。
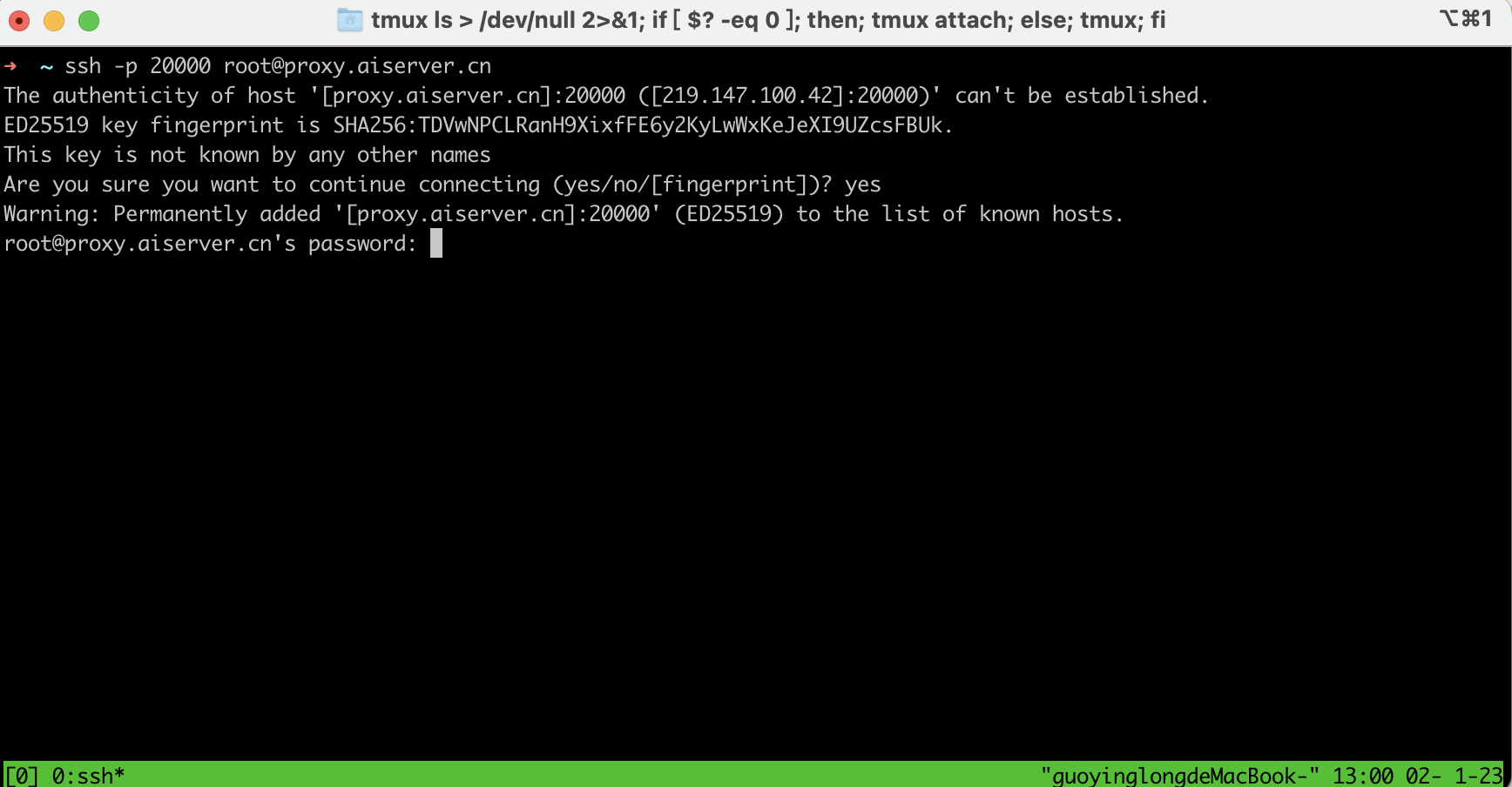
回车后需要输入连接密码,在
我的任务页面点击复制密码按钮。右键粘贴密码(密码在终端上不显示),再回车即可成功连接到任务。
# 安装软件包
思腾云上的镜像中包含基础软件
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116 -i https://pypi.tuna.tsinghua.edu.cn/simple
1
# 运行简单AI测试程序
# 生成main.py文件
在/root下创建main.py文件,添加如下内容:
import argparse
import os
import random
import shutil
import time
import warnings
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.distributed as dist
import torch.optim
import torch.multiprocessing as mp
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision.models as models
parser = argparse.ArgumentParser(description='PyTorch ImageNet Training')
parser.add_argument('-j', '--workers', default=8, type=int, metavar='N',
help='number of data loading workers (default: 4)')
parser.add_argument('--epochs', default=1, type=int, metavar='N',
help='number of total epochs to run')
parser.add_argument('--start-epoch', default=0, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('-b', '--batch-size', default=256, type=int,
metavar='N',
help='mini-batch size (default: 256), this is the total '
'batch size of all GPUs on the current node when '
'using Data Parallel or Distributed Data Parallel')
parser.add_argument('--lr', '--learning-rate', default=0.1, type=float,
metavar='LR', help='initial learning rate', dest='lr')
parser.add_argument('--momentum', default=0.9, type=float, metavar='M',
help='momentum')
parser.add_argument('--wd', '--weight-decay', default=1e-4, type=float,
metavar='W', help='weight decay (default: 1e-4)',
dest='weight_decay')
parser.add_argument('-p', '--print-freq', default=10, type=int,
metavar='N', help='print frequency (default: 10)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='path to latest checkpoint (default: none)')
parser.add_argument('-e', '--evaluate', dest='evaluate', action='store_true',
help='evaluate model on validation set')
parser.add_argument('--pretrained', dest='pretrained', action='store_true',
help='use pre-trained model')
parser.add_argument('--world-size', default=-1, type=int,
help='number of nodes for distributed training')
parser.add_argument('--rank', default=-1, type=int,
help='node rank for distributed training')
parser.add_argument('--dist-url', default='tcp://224.66.41.62:23456', type=str,
help='url used to set up distributed training')
parser.add_argument('--dist-backend', default='nccl', type=str,
help='distributed backend')
parser.add_argument('--seed', default=None, type=int,
help='seed for initializing training. ')
parser.add_argument('--gpu', default=None, type=int,
help='GPU id to use.')
parser.add_argument('--multiprocessing-distributed', action='store_true',
help='Use multi-processing distributed training to launch '
'N processes per node, which has N GPUs. This is the '
'fastest way to use PyTorch for either single node or '
'multi node data parallel training')
class Ds(torch.utils.data.Dataset):
def __init__(self):
self.roidb = [0 for i in range(100000)]
def __getitem__(self, index):
id = self.roidb[index]
return torch.randn(3,224,224), torch.tensor(1,dtype=torch.long)
def __len__(self):
return len(self.roidb)
def main():
args = parser.parse_args()
if args.dist_url == "env://" and args.world_size == -1:
args.world_size = int(os.environ["WORLD_SIZE"])
args.distributed = args.world_size > 1 or args.multiprocessing_distributed
ngpus_per_node = torch.cuda.device_count()
if args.multiprocessing_distributed:
# Since we have ngpus_per_node processes per node, the total world_size
# needs to be adjusted accordingly
args.world_size = ngpus_per_node * args.world_size
# Use torch.multiprocessing.spawn to launch distributed processes: the
# main_worker process function
mp.spawn(main_worker, nprocs=ngpus_per_node, args=(ngpus_per_node, args))
else:
# Simply call main_worker function
main_worker(args.gpu, ngpus_per_node, args)
def main_worker(gpu, ngpus_per_node, args):
global best_acc1
args.gpu = gpu
if args.gpu is not None:
print("Use GPU: {} for training".format(args.gpu))
if args.distributed:
if args.dist_url == "env://" and args.rank == -1:
args.rank = int(os.environ["RANK"])
if args.multiprocessing_distributed:
# For multiprocessing distributed training, rank needs to be the
# global rank among all the processes
args.rank = args.rank * ngpus_per_node + gpu
dist.init_process_group(backend=args.dist_backend, init_method=args.dist_url,
world_size=args.world_size, rank=args.rank)
# create model
model = models.resnet101()
if args.distributed:
# For multiprocessing distributed, DistributedDataParallel constructor
# should always set the single device scope, otherwise,
# DistributedDataParallel will use all available devices.
if args.gpu is not None:
torch.cuda.set_device(args.gpu)
model.cuda(args.gpu)
# When using a single GPU per process and per
# DistributedDataParallel, we need to divide the batch size
# ourselves based on the total number of GPUs we have
args.batch_size = int(args.batch_size / ngpus_per_node)
args.workers = int((args.workers + ngpus_per_node - 1) / ngpus_per_node)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu])
else:
model.cuda()
# DistributedDataParallel will divide and allocate batch_size to all
# available GPUs if device_ids are not set
model = torch.nn.parallel.DistributedDataParallel(model)
elif args.gpu is not None:
torch.cuda.set_device(args.gpu)
model = model.cuda(args.gpu)
else:
# DataParallel will divide and allocate batch_size to all available GPUs
if args.arch.startswith('alexnet') or args.arch.startswith('vgg'):
model.features = torch.nn.DataParallel(model.features)
model.cuda()
else:
model = torch.nn.DataParallel(model).cuda()
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(args.gpu)
optimizer = torch.optim.SGD(model.parameters(), args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)
# optionally resume from a checkpoint
if args.resume:
if os.path.isfile(args.resume):
print("=> loading checkpoint '{}'".format(args.resume))
if args.gpu is None:
checkpoint = torch.load(args.resume)
else:
# Map model to be loaded to specified single gpu.
loc = 'cuda:{}'.format(args.gpu)
checkpoint = torch.load(args.resume, map_location=loc)
args.start_epoch = checkpoint['epoch']
best_acc1 = checkpoint['best_acc1']
if args.gpu is not None:
# best_acc1 may be from a checkpoint from a different GPU
best_acc1 = best_acc1.to(args.gpu)
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
print("=> loaded checkpoint '{}' (epoch {})"
.format(args.resume, checkpoint['epoch']))
else:
print("=> no checkpoint found at '{}'".format(args.resume))
cudnn.benchmark = True
train_dataset = Ds()
if args.distributed:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
else:
train_sampler = None
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size, shuffle=(train_sampler is None),
num_workers=args.workers, pin_memory=True, sampler=train_sampler)
if args.evaluate:
validate(val_loader, model, criterion, args)
return
for epoch in range(args.start_epoch, args.epochs):
begin = time.time()
if args.distributed:
train_sampler.set_epoch(epoch)
# train for one epoch
train(train_loader, model, criterion, optimizer, epoch, args)
end = time.time()
print(end - begin)
# evaluate on validation set
def train(train_loader, model, criterion, optimizer, epoch, args):
batch_time = AverageMeter('Time', ':6.3f')
data_time = AverageMeter('Data', ':6.3f')
losses = AverageMeter('Loss', ':.4e')
progress = ProgressMeter(
len(train_loader),
[batch_time, data_time, losses],
prefix="Epoch: [{}]".format(epoch))
# switch to train mode
model.train()
end = time.time()
for i, (images, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
if args.gpu is not None:
images = images.cuda(args.gpu, non_blocking=True)
target = target.cuda(args.gpu, non_blocking=True)
# compute output
output = model(images)
loss = criterion(output, target)
# measure accuracy and record loss
losses.update(loss.item(), images.size(0))
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0:
progress.display(i)
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self, name, fmt=':f'):
self.name = name
self.fmt = fmt
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def __str__(self):
fmtstr = '{name} {val' + self.fmt + '} ({avg' + self.fmt + '})'
return fmtstr.format(**self.__dict__)
class ProgressMeter(object):
def __init__(self, num_batches, meters, prefix=""):
self.batch_fmtstr = self._get_batch_fmtstr(num_batches)
self.meters = meters
self.prefix = prefix
def display(self, batch):
entries = [self.prefix + self.batch_fmtstr.format(batch)]
entries += [str(meter) for meter in self.meters]
print('\t'.join(entries))
def _get_batch_fmtstr(self, num_batches):
num_digits = len(str(num_batches // 1))
fmt = '{:' + str(num_digits) + 'd}'
return '[' + fmt + '/' + fmt.format(num_batches) + ']'
def adjust_learning_rate(optimizer, epoch, args):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
lr = args.lr * (0.1 ** (epoch // 30))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
if __name__ == '__main__':
main()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
# 运行main.py
NCCL_IB_DISABLE=0 NCCL_DEBUG=INFO \
python3 main.py -b 147 \
--dist-url 'tcp://127.0.0.1:3754' \
--dist-backend 'nccl' \
--multiprocessing-distributed \
--world-size 1 \
--rank 0 \
--epochs 5
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
上次更新: 2024/03/28, 16:03:00